Fortigate Cluster Protocol (FGCP) - High Availability - Parte 1
- Iñaki Urrutxi

- 12 mar 2020
- 4 Min. de lectura
Actualizado: 3 may 2020

Empiezo mi primer blog y espero que no sea el último, voy a desarrollar un tema sobre el que llevo queriendo escribir hace tiempo. El HA de Fortigate, a priori parece sencillo, vía GUI en 1 minuto podemos activarlo, pero explicaremos algunos de esos comandos que aparecen vía GUI y otros que se pueden activar vía CLI. Mediante un serie de blogs intentare dar un poco de luz sobre algunos conceptos que nos ayudaran a configurar mejor nuestros clusters de HA.

Vía GUI solo hace falta seleccionar el modo Activo-Pasivo/Activo-Activo, la prioridad de los miembros, el grupo y la clave, los interfaces a monitorizar y los puertos de HA. Podemos mantener las sesiones sincronizadas entre los miembros del cluster(hasta 4 FWs) así como utilizar otros interfaces para la gestión independiente de cada Fortigate o seleccionar si queremos que esa sincronización se realice con paquetes L2 o paquetes L3. Lo preferible es que para hacer el HA se use un cable directo entre FWs, por este cable se genera el cluster, se sincroniza la configuración y las sesiones activas entre los diferentes FWs.
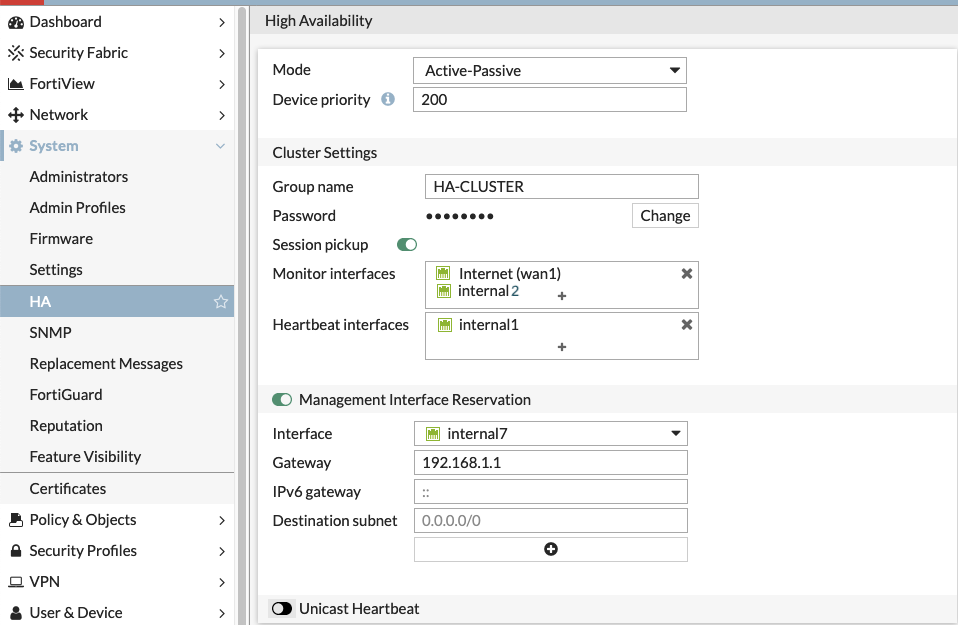
Cuando se forma el cluster, salvo que reservemos unos interfaces para monitorizar los Fws de manera independiente, solo tenemos acceso al equipo con mayor prioridad, el otro esta esperando a que el equipo con mayor prioridad se caiga o que alguno de los interfaces monitorizados caigan, para cambiar el roll.
Fortigate consigue esto generando unas macs virtuales en cada interface que solo la tiene el equipo activo, cuando este equipo cae esa mac pasa al equipo de backup. Esta mac se calcula con esta formula:
00–09–0f-09-<group-id_hex>-(<vcluster_integer> + <idx>))<group-id_hex> → Group-id en hexadecimal <vcluster_integer> → Virtual cluster1, 2, asociado a los virtual domains <idx> → Número de interface del FW
Para evitar conflictos de ips con varios cluster funcionando en la misma red os recomiendo que uséis un group-id diferente para cada cluster.
Configuración básica en un cluster HA en el FW MASTER y en el FW SLAVE
DEVICE 1 - MASTER
config system ha
set group-id 10
set group-name “HA-CLUSTER”
set mode a-p
set hbdev “internal1” 50
set session-pickup enable
set override enable
set priority 200
set sync-config enable
set monitor “wan1” "internal2"
endDEVICE 2 - SLAVE
config system ha
set group-id 10
set group-name “HA-CLUSTER”
set mode a-p
set hbdev “internal1” 50
set session-pickup enable
set override enable
set priority 100
set sync-config enable
set monitor “wan1” "internal2"
endDesarrollamos estos comando y otros:
Interface o Interfaces por los que se realiza el HA, pueden ser directos o pasar por SW de L2(Verificar que esos SW no filtran los paquetes de HA)
set hbdev “internal1” 50Sincronizar sesiones TCP entre el FG-main y el FG-Backup
set session-pickup enable (desactivado por defecto)El equipo con mayor prioridad será el FG-main
set priority 190Sincronizar la configuración entre ambos FWS
set sync-config enable (activado por defecto)Monitorizar el estado de determinados interfaces
set monitor “wan1”Se encripta y autentifica la información entre clusters
set encryption enable (desactivado por defecto)
set authentication enable (desactivado por defecto)Por defecto solo se sincronizan aquellas sessiones TCP que no pasan por políticas que tengan perfiles de seguridad activados, pero sincronizar otro tipo de sesiones
set session-pickup-connectionless enable(desactivado por defecto)
set session-pickup-expectation enable (desactivado por defecto)Gestionar Fws de manera independiente a través de 1 interface especifico. Este interface no se sincroniza con el FW de backup
set ha-mgmt-status enable
set ha-mgmt-interface internal7
set ha-mgmt-interface-gateway 192.168.1.11- DEVICE MASTER - interface port7
config system interface
edit “internal7”
set ip 192.168.1.10 255.255.255.0
set allowaccess ping https ssh
set type physical
next
end2- DEVICE SLAVE - interface port7
config system interface
edit “internal7”
set ip 192.168.1.20 255.255.255.0
set allowaccess ping https ssh
set type physical
next
endEl comando override tiene una mención especial, cuando esta activado el equipo con mayor prioridad se pondra siempre como MASTER del cluster, esto puede provocar más interrupciones del tráfico, pero te aseguras que ese equipo será siempre el master del cluster, pero cuando override está desactivado a la hora de elegir el FW master se hace primero por el tiempo que lleva el dispositivo arrancado y segundo por la prioridad de mismo.
set override enable (desactivado por defecto)Cuando un interface o un equipo falla y se realiza el cambio de roll, el equipo que se pone como master manda unos gratuitos ARPs para que los equipos de la red actualicen su tabla de arps, esto mejora la convergencia.
set gratuitous-arps enable (activado por defecto)En algunos casos puede que mandando esos G-ARPs no sea suficiente, el FW tiene otra funcionalidad, durante un segundo tira los interfaces del FW para fozar a los equipos de la red a cambiar la tabla ARP
set link-failed-signal enable (desactivado por defecto)Por defecto a la hora de actualizar los equipos de un cluster, primero se actualiza el equipo de backup, si se realiza correctamente se mete en el cluster se pone como master y se actualiza el otro dispositivo, esto hace que dependiendo del modelo de dispositivo esto pueda alargar la actualización, para evitarlo podemos actualizar ambos equipos a la vez.
set uninterruptible-upgrade disable (activado por defecto)Cuando trabajamos con virtual domains(vdoms) podemos hacer que unos funcionen sobre el FW main y otro sobre el FW backup
set vcluster2 enable (desactivado por defecto)Desarrollaremos este concepto de cluster con virtual domains, así como diferencias entre modo a-p y a-a, FGCP vs FGSP, comandos de diagnóstico y mucho más es proximos blogs.


Comentarios